Written by Philipp on 2023-11-20
Fixing Issues after upgrading Proxmox 7 to 8
CLI . Network . ProxmoxMy initial plan was to update all of my Proxmox nodes to the latest version by the end of this year. While most updates proceeded smoothly, I encountered two errors on one particular node. Given that updating servers is a critical operation, especially when they are only remotely accessible via the network, I decided to
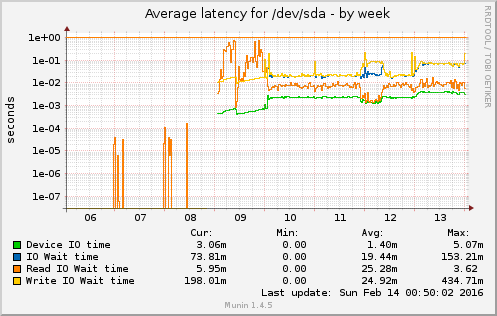
Written by Philipp on 2016-02-14
Disk failure and suprises
Bash . Proxmox . VirtualisierungOnce in a while – and especially if you have a System with an uptime > 300d – HW tends to fail. Good thing, if you have a Cluster, where you can do the maintance on one Node, while the import stuff is still running on the other ones. Also good to always have a