Written by Philipp on 2020-04-26
Fixing nix Setup on MacOS Catalina
Bash . CLI . Mac . PersonalWith MacOS Catalina (10.15), Apple decided to decrease the possibilities of system users to install software applications within the system. That means, that it is not possible anymore to install software at specific location in your system, since most system folder ware mounted read-only at boot to improve the overall system security. That leads to
Written by Philipp on 2016-02-14
Disk failure and suprises
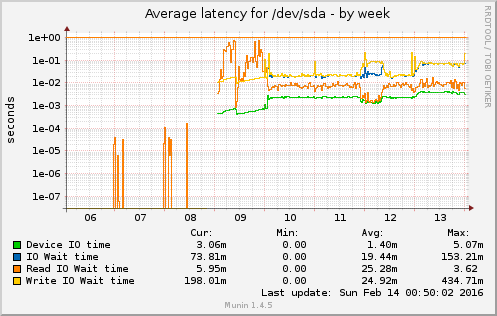
Bash . Proxmox . VirtualisierungOnce in a while – and especially if you have a System with an uptime > 300d – HW tends to fail. Good thing, if you have a Cluster, where you can do the maintance on one Node, while the import stuff is still running on the other ones. Also good to always have a
Written by Philipp on 2014-12-05
Writing Munin Plugins pt3: some Stats about VMWare Fusion
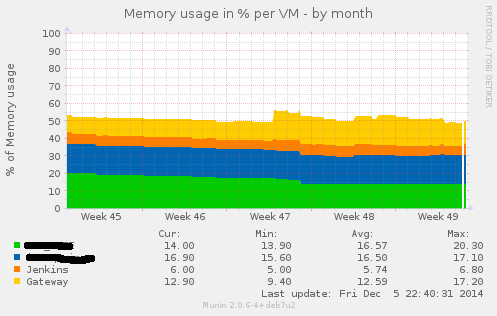
Bash . Graphics . Perl . VirtualisierungIn a project where we had the need for VMs being capable of doing CI for Java and also doing CI for iOS Application (using XCode Build Bots), we decided to go with a Mac OS Server as the Host Platform and using VMWare Fusion as the base Virtualisation System. We had several VMs there

Written by Philipp on 2014-06-22
Writing Munin Plugins pt1: Overview
Bash . Mac . NetworkWriting your own Munin Plugins Around February this year, we at innoQ had the need for setting up a Mac OS based CI for a Project. Besides building of integrating some standard Java Software, we also had to setup an Test Environment with Solaris/Weblogic, Mac OS for doing a CI for an iOS Application and
Written by Philipp on 2012-10-03
Command to Print Out Directory Tree Listing
Bash . Snippetsls -R | grep “:$” | sed -e ‘s/:$//’ -e ‘s/[^-][^\/]*\//–/g’ -e ‘s/^/ /’ -e ‘s/-/|/’ Found here
Written by Philipp on 2009-02-23
sophisticated Backups mit Rsync Part II
Bash . ToolingVersion 3.1 Features: Logs werden nun gzip komprimiert wöchentliche Backups aus der vorherigen Woche werden tar.gz komprimiert #!/bin/sh # Philipp’s backup-scripte version 3.1 ROOT=`pwd` BACKDIR=$ROOT/backup D=`eval date +%Y-%m-%d` W=`eval date +%Y-%W` w=`eval date +%w` LATEST=”latest” EXCLUDE=$ROOT/exclude.txt SOURCES=$ROOT/sources.txt LOG=$ROOT/log/$D.log # Array mit allen ben‚‚tigten Verzeichnissen und Ordnern folders=( $ROOT/log ) files=( $EXCLUDE $SOURCES $LOG) for
Written by Philipp on 2009-02-17
instant jruby & derby environment für eine RoR Anwendung
Bash . Build . Java . ruby . Ruby on Rails . ToolingAls angestammter Java-Entwickler geht es mir oftmals schwer von der Hand, einer Ruby on Rails (RoR) Anwendung mit relativ wenig Aufwand eine brauchbare Laufzeitumgebung zu bieten. Normalerweise sollte das OS (MacOS 10.5.6) alles Brauchbare bieten. So ist oftmals eine Rails-Version installiert und auch das (standardmäßig genutzte) SQlite 3 ist vorhanden. Dennoch sind es oftmals Plugins
Written by Philipp on 2008-11-23
sophisticated Backups mit Rsync
Bash . ToolingBackups sind wichtig. Jeder der einmal vor einer kaputten, ratternden Festplatte gesessen hat, weiß wie frustrierend das Wissen ist, alle seine Daten ins informationstechnische Nirwana entschwinden zu sehen. Ist ein Backup der persönlichen Daten noch mit relativ geringem Aufwand möglich (so es denn regelmäßig veranstaltet wird), so wird ein Backup eines Server-Systems in vielen Dingen