
Written by Philipp on 2026-04-18
Running gokrazy on a Banana Pi BPI-R1
CLI . Go . Hacking . TestingMotivation I had a BPI-R1 sitting in a drawer. The board is from 2014 — only ancient OpenWrt and outdated Armbian images exist for it. Nobody maintains this platform anymore. The hardware is fine though: dual-core Allwinner A20, 1GB RAM, SATA, and a BCM53125 5-port Gigabit switch on the board. Not bad for a dedicated
Written by Philipp on 2023-11-20
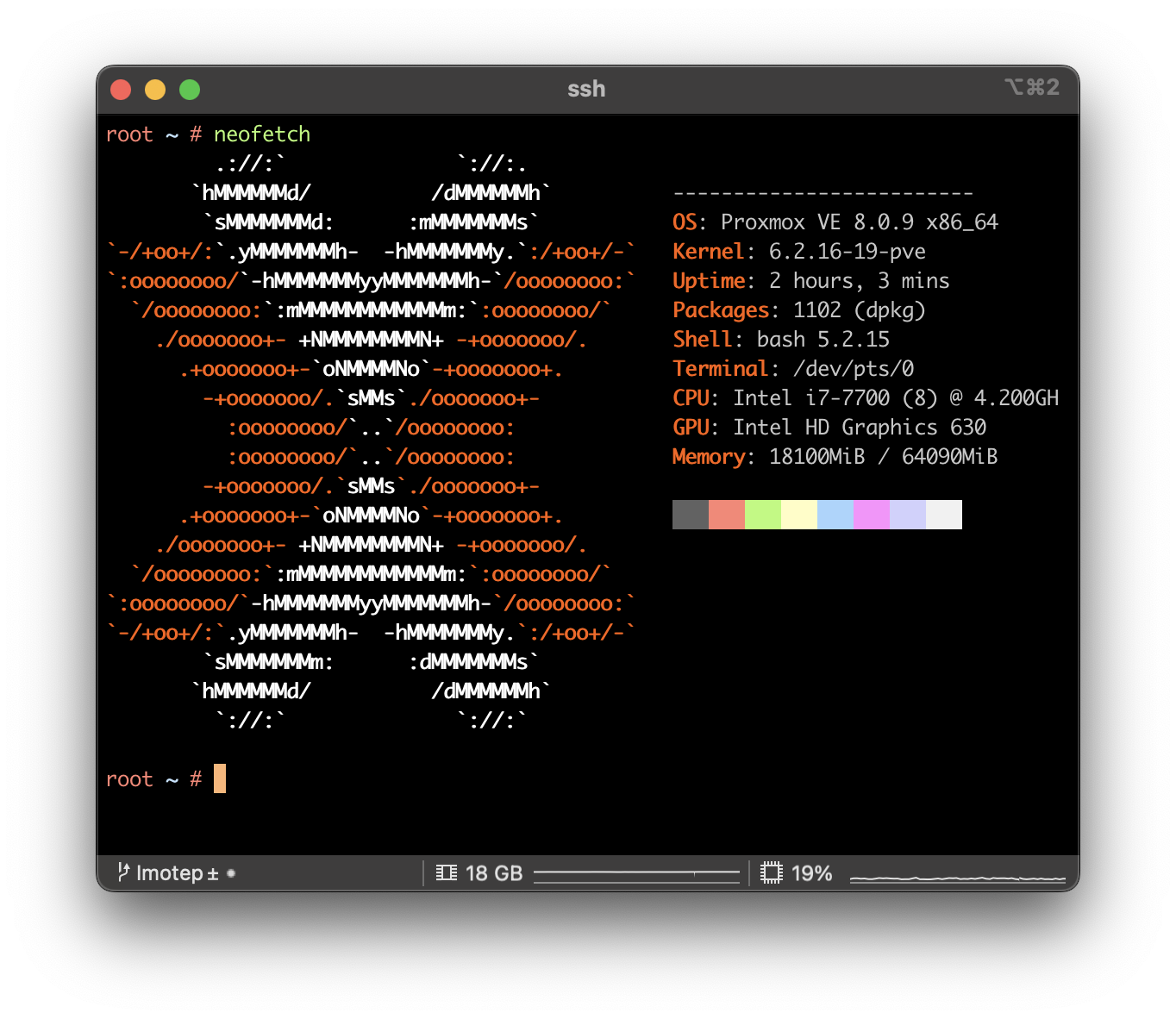
Fixing Issues after upgrading Proxmox 7 to 8
CLI . Network . ProxmoxMy initial plan was to update all of my Proxmox nodes to the latest version by the end of this year. While most updates proceeded smoothly, I encountered two errors on one particular node. Given that updating servers is a critical operation, especially when they are only remotely accessible via the network, I decided to

Written by Philipp on 2023-02-13
Fixing Error “failed, reason: getaddrinfo EAI_AGAIN” in Gitlab Builds
Build . Gitlab . TechSome days ago, I detected some new errors in one of our builds pipelines. The interesting part is, that there were no changes done, that might have caused this error.One example for this error was an DNS resolution error using npm: After some digging, I found out, that the only update might have come with

Written by Philipp on 2023-01-07
Create CSV Reports from GIT Repositories containing your commits
ToolingSome months ago, I got the need to run over several GIT Repositories and collect the work I did on each day. The play was to gather all the data and collect them in different CSV files.Since I wasn’t able to find a ready script for this task, I guess it is a good candidate

Written by Philipp on 2023-01-05
Teaching Mailcow how to deal with Ham/Spam
ToolingThe good must be put in the dish, the bad you may eat if you wish. Cinderella Mailcow is a groupware solutions, that is mainly used for email messaging. With Mailcow, you can setup your own Docker-based Mail-Server + Addons. Mailcow uses rspamd to filter out Spam Messages.However, after some time, there is a need to fine-tune the Spam

Written by Philipp on 2023-01-03
Using the MacOS airport utility
ToolingUsing the MacOS airport utility. Sometimes you need to gather information abouth your current WiFi Connection of you Mac via CLI only (maybe you just have a remote SSH Connection to do so). With the airport tool, there is a handy utility to perform most of the tasks, that you would normally do via the UI. You
Written by Philipp on 2020-04-26
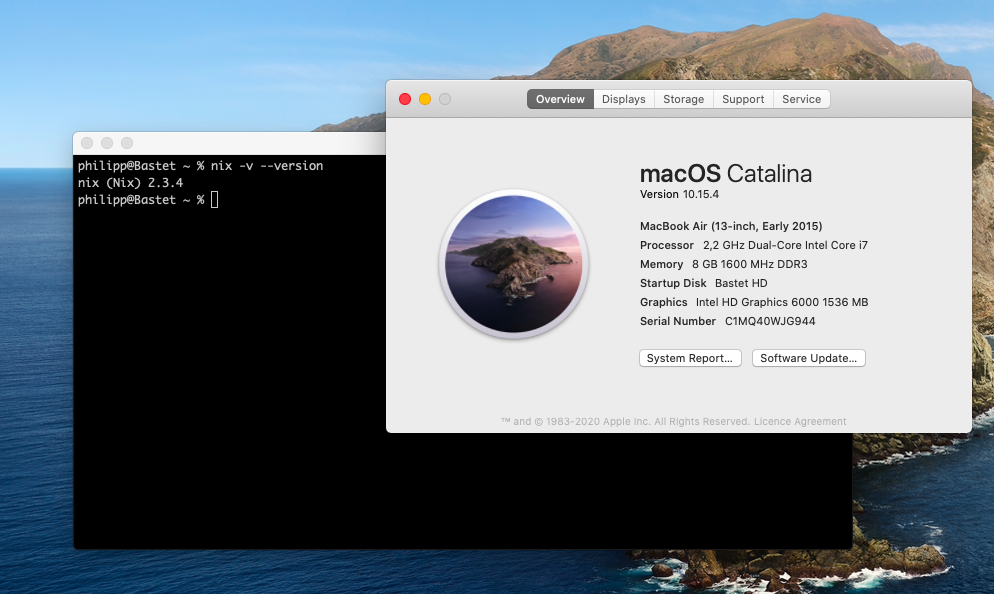
Fixing nix Setup on MacOS Catalina
Bash . CLI . Mac . PersonalWith MacOS Catalina (10.15), Apple decided to decrease the possibilities of system users to install software applications within the system. That means, that it is not possible anymore to install software at specific location in your system, since most system folder ware mounted read-only at boot to improve the overall system security. That leads to

Written by Philipp on 2018-01-27
How to disable the www-data user to send emails with postfix
Security . ToolingSometimes an insecure configuration allows spammer to use the www-data user to send emails with you postfix server. Normally this is the case, when you get a bunch of error email from your mailserver, that some emails from www-data@hostname.tld could not be delivered. To be sure, that this situation cannot exist, you can add the

Written by Philipp on 2017-12-12
20min Handson ZFS
Tech . Tooling . ZFSZFS is often called the last word in file systems. It is a new approach to deal with large pools of disks originally invented by Sun. It was later then ported to FreeBSD, MacOS (only 10.5) and Linux. This text should show some of the basic feature of ZFS and demonstrate them handson by example.

Written by Philipp on 2017-05-04
solving Security Error while starting Java WebStart (e.g. IPMI Remote)
Mac . Security . ToolingMost of the IPMI Systems out there still using good old Java based Remote Applications to connect to the remote console. Sine Java 8 update 111, the MD5 singing algorithm was marked as insecure (aka disabled) by Oracale (see Relase Notes for that Release ” Restrict JARs signed with weak algorithms and keys”). You will