Written by Philipp on 2012-02-19
Counter Update
DB . Java . Play! FrameworkI just finished my latest improvements to the legacy version of my counter script. I just added the lookup for ISPs and added dynamic scaling for the axis legend. I will now going forward to change the whole system to a more sophisticated software, e.g. using a Datawarehouse approach. The first version of the Data-Model
Written by Philipp on 2007-12-13
Abbilden der Relationen
DB . Java . Personal . ToolingNachdem ich alle notwendigen Relationen in der Datenbank abgebildet habe, habe ich jetzt meine Annotations zwischen den Objekten fertig gestellt. Es gibt ein paar interessante Dinge, so zum Beispiel eine rekursive Relation innerhalb von 2 Tasks (Aufgaben). Das heißt, eine Aufgabe kann n Unteraufgaben haben. Weiterhin enthält jede Aufgaben ein Array von Empfängern und einen
Written by Philipp on 2007-12-07
[PP] ProblemPost
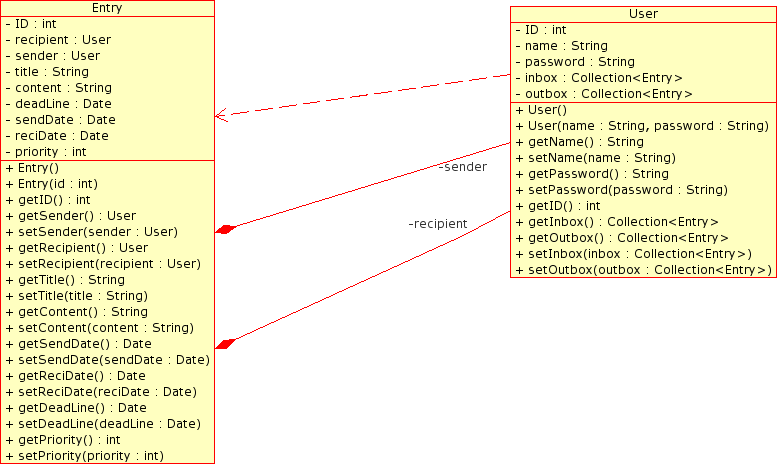
DB . Java . PersonalSoooo da das ja bei den Benutzern schon so wunderbar klappt, hier dann mal meine Probleme: Wie in einem der letzten Posts erwähnt, möchte ich gerne eine Abhängigkeit meiner Entries untereinander haben. Das heißt, ich möchte unter einem Eintrag n Untereinträge haben. Das Klassendiagramm schaut dann so aus: Meine Tabelle sieht so aus: Ja eigentlich
Written by Philipp on 2007-10-22
JPA YEEHA!
DB . Java . PersonalBesser später als nie, hier also dann mal – nach laaaanger Zeit mal wieder – mein aktueller Status. Mittlerweile bin ich ein ganzes Stück weiter und so fange ich sogar an, dem ganzen System von Persistence etwas abgewinnen zu können. Einzig die Frage bleibt, wieso JPA per default partout alle Feldnamen als groß schreibt. Naja
Written by Philipp on 2007-10-09
Betr. JPA
DB . PersonalBisher hat der Umbau der vorhanden Klassen hinsichtlich der Nutzung von JPA promblemloser funktioniert als gedacht. Bisher versuche ich halt nur, das User Objekt aus der Tabelle User auszulesen. Letztendlich muss ich aber mein bisheriges Konzept soweit umstellen, dass ich die Validierung von Eingaben aus der User Klasse in eine sperate Application Klasse auslagere. Allen
Written by Philipp on 2007-10-06
Was bisher so geschieht…
DB . Java . Personal . ToolingMoin… Ich wollte mal wieder ein wenig Feedback geben, woran ich bisher so sitze… Letztendlich bin ich endlich mit einer schönen Datenbankklasse ausgestattet, die mir auch die Dinge bietet, auf die ich angewiesen sein werde – ob da jetzt noch etwas dazu kommt, wird sich zeigen, aber erstmal reicht mir das, was bisher vorhanden ist.