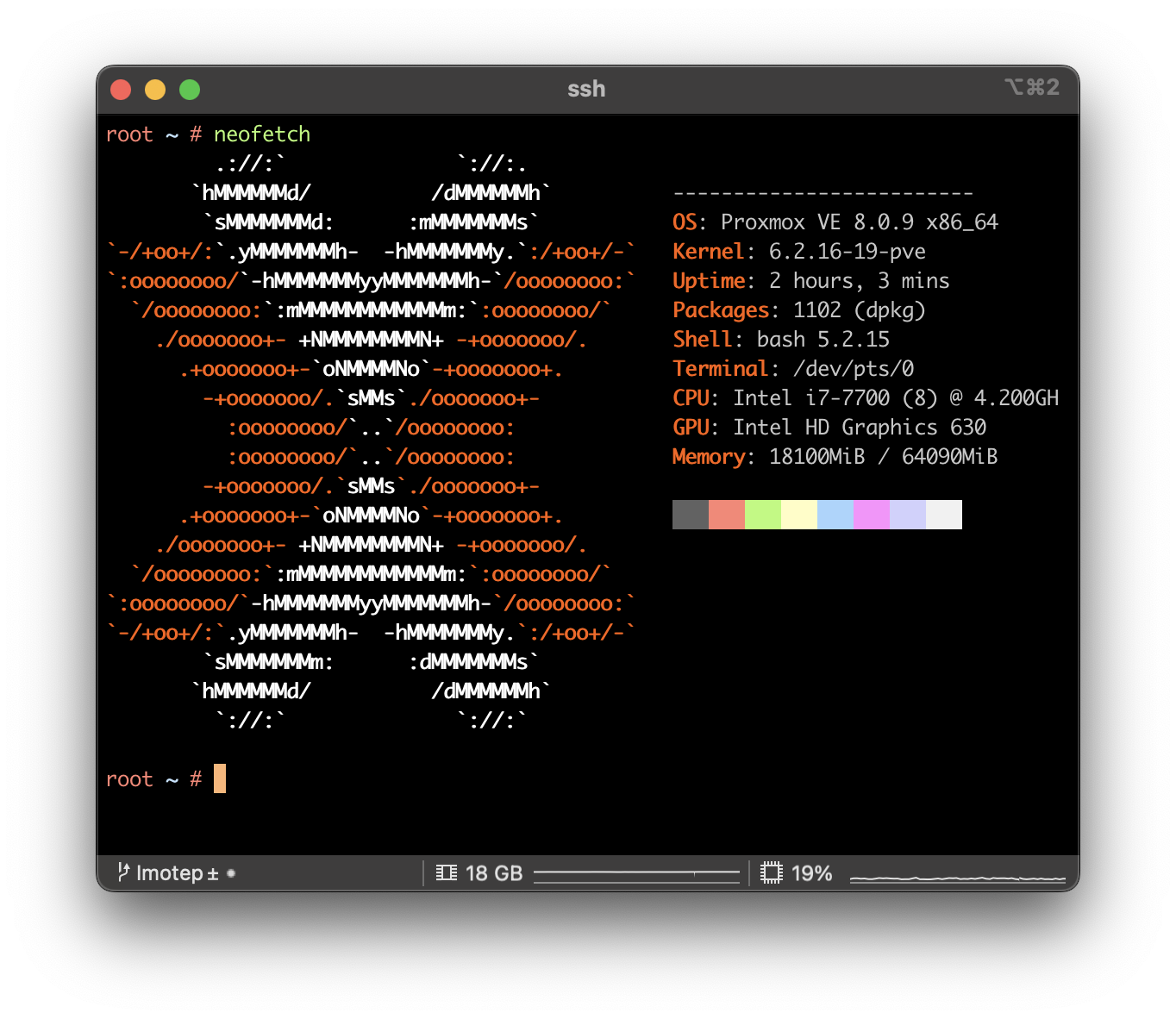
Written by Philipp on 2023-11-20
Fixing Issues after upgrading Proxmox 7 to 8
CLI . Network . ProxmoxMy initial plan was to update all of my Proxmox nodes to the latest version by the end of this year. While most updates proceeded smoothly, I encountered two errors on one particular node. Given that updating servers is a critical operation, especially when they are only remotely accessible via the network, I decided to
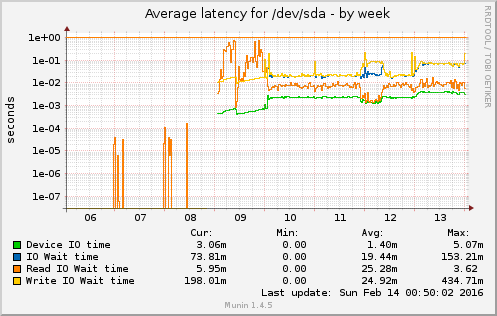
Written by Philipp on 2016-02-14
Disk failure and suprises
Bash . Proxmox . VirtualisierungOnce in a while – and especially if you have a System with an uptime > 300d – HW tends to fail. Good thing, if you have a Cluster, where you can do the maintance on one Node, while the import stuff is still running on the other ones. Also good to always have a

Written by Philipp on 2015-09-29
Install CoreOS on Proxmox
Network . Tooling . Uncategorized . VirtualisierungSome words before we start… Hello Blog, it’s been a while. I still have to deliver the last part of the Munin Plugin Development Series (Part 1, 2, 3). Today I would like to write something about the Setup of a CoreOS Environment on Proxmox. Proxmox is a Debian based Distribution that bundles a Web
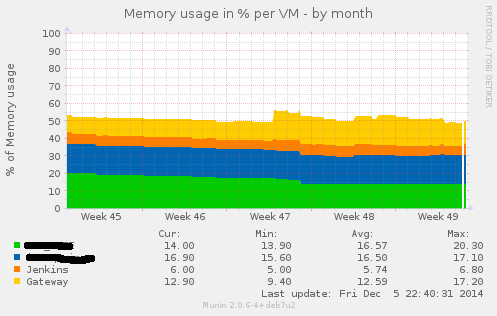
Written by Philipp on 2014-12-05
Writing Munin Plugins pt3: some Stats about VMWare Fusion
Bash . Graphics . Perl . VirtualisierungIn a project where we had the need for VMs being capable of doing CI for Java and also doing CI for iOS Application (using XCode Build Bots), we decided to go with a Mac OS Server as the Host Platform and using VMWare Fusion as the base Virtualisation System. We had several VMs there

Written by Philipp on 2013-07-31
Creating a SmartOS Dataset for Windows Server 2012 r2
SmartOS . VirtualisierungI postet about SmartOS almost 1 1/2 Year ago. Since i am still using SmartOS here and then for primary testing purpose, i decided to create a new Post about how to make your own Datasets, to make several VMs based on the same Image possible. As Microsoft also introduces their latest Server OS (Windows

Written by Philipp on 2012-02-18
Joyent SmartOS VM MYSQL Setup
SmartOS . Tooling . VirtualisierungI just played around with the new SmartOS from Joyent ( Homepage ). I followed a basic tutorial from a Blog called opusmagnus to setup my basic SmartOS Machine on Virtualbox. You basically just have to insert the latest iso image and startup the VM (SmartOS is a system that runs from a live Medium

Written by Philipp on 2011-12-05
WIP – Working in Progress
Hacking . VirtualisierungI just installed OpenIndiana with a ZFS Raid z1 on an old 1HE Rack Server. I was also able to make VirtualBox running :-). It looks like there will be some fun in the nearer future!
Written by Philipp on 2011-06-22
VirtualBox VMs auf Dual-Boot Systemen (FAT32 & 2GB Split Images)
Tech . VirtualisierungDie Nutzung von Dual-Boot Systemen (Linux/Windows oder Mac-OS/Windows) bietet sich manchmal an, um vielleicht neben der gängigen Arbeit auch noch mal ein Spiel zocken zu können. Oder es ist einfach notwendig, eine VM auf einem mobilen Datenträge für die Nutzung auf unterschiedlichen Betriebssystemen zu verwenden. Das einzige Dateisystem, welches auf allen aktuellen OS-Version ohne die
Written by Philipp on 2009-05-17
VirtualBox error: fixing VDI already registered
VirtualisierungOftmals ist es zweckmäßig, eine Art Template-Image für eine virtuelle Maschine (VM) zu erstellen, mit welchem man eine saubere Basis erhält, auf der man Software installieren kann, speziell für die einzelne VM. Das Problem ist, dass VirtualBox in jedes VDI (virtual disk image) eine eindeutige ID schreibt, welche es verhindert, dass eine identische Copy eines