Disk failure and suprises
Bash . Proxmox . VirtualisierungOnce in a while – and especially if you have a System with an uptime > 300d – HW tends to fail.
Good thing, if you have a Cluster, where you can do the maintance on one Node, while the import stuff is still running on the other ones. Also good to always have a Backup of the whole content, if a disk fails.
One word before I continue: Regarding Software-RAIDs: I had a big problem once with a HW RAID Controller going bonkers and spent a week to find another matching controller to get the data back. At least for redundant Servers it is okay for me to go with SW RAID (e.g. mdraid). And if you can, you should go with ZFS in any case :-).
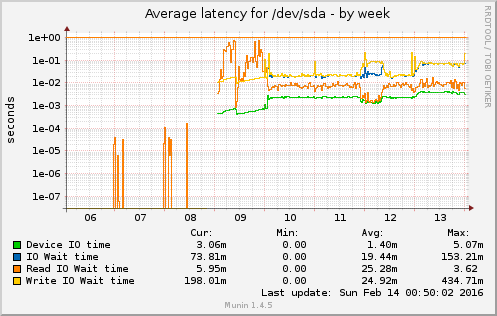
Anyhow, if you see graphs like this one:
You know that something goes terribly wrong.
Doing a quick check, states the obvious:
# cat /proc/mdstat
Personalities : [raid1]
md3 : active raid1 sda4[0](F) sdb4[1]
1822442815 blocks super 1.2 [2/1] [_U]
md2 : active raid1 sda3[0](F) sdb3[1]
1073740664 blocks super 1.2 [2/1] [_U]
md1 : active raid1 sda2[0](F) sdb2[1]
524276 blocks super 1.2 [2/1] [_U]
md0 : active raid1 sda1[0](F) sdb1[1]
33553336 blocks super 1.2 [2/1] [_U]
unused devices: <none>
So /dev/sda seems to be gone from the RAID. Let’s do the checks.
Hardware check
hdparm:
# hdparm -I /dev/sda
/dev/sda:
HDIO_DRIVE_CMD(identify) failed: Input/output error
smartctl:
# smartctl -a /dev/sda
smartctl 5.41 2011-06-09 r3365 [x86_64-linux-2.6.32-34-pve] (local build)
Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net
Vendor: /0:0:0:0
Product:
User Capacity: 600,332,565,813,390,450 bytes [600 PB]
Logical block size: 774843950 bytes
scsiModePageOffset: response length too short, resp_len=47 offset=50 bd_len=46
>> Terminate command early due to bad response to IEC mode page
A mandatory SMART command failed: exiting. To continue, add one or more '-T permissive' options.
/dev/sdais dead, Jim
Next thing is to schedule a Disk Replacement and moving all services to another host/prepare the host to shutdown for maintenance.
Preparation for disk replacement
Stop all running Containers:
# for VE in $(vzlist -Ha -o veid); do vzctl stop $VE; done
I also disabled the “start at boot” option to have a quick startup of the Proxmox Node.
Next: Remove the faulty disk from the md-RAID:
# mdadm /dev/md0 -r /dev/sda1
# mdadm /dev/md1 -r /dev/sda2
# mdadm /dev/md2 -r /dev/sda3
# mdadm /dev/md3 -r /dev/sda4
Shutting down the System.
… some guy in the DC moved to the server at the expected time and replaces the faulty disk …
After that, the system is online again.
- copy partition table from
/dev/sdbto/dev/sda# sgdisk -R /dev/sda /dev/sdb - recreate the GUID for
/dev/sda# sgdisk -G /dev/sda
Then add /dev/sda to the RAID again.
# mdadm /dev/md0 -a /dev/sda1
# mdadm /dev/md1 -a /dev/sda2
# mdadm /dev/md2 -a /dev/sda3
# mdadm /dev/md3 -a /dev/sda4
# cat /proc/mdstat
Personalities : [raid1]
md3 : active raid1 sda4[2] sdb4[1]
1822442815 blocks super 1.2 [2/1] [_U]
[===>.................] recovery = 16.5% (301676352/1822442815) finish=329.3min speed=76955K/sec
md2 : active raid1 sda3[2] sdb3[1]
1073740664 blocks super 1.2 [2/2] [UU]
md1 : active raid1 sda2[2] sdb2[1]
524276 blocks super 1.2 [2/1] [_U]
resync=DELAYED
md0 : active raid1 sda1[2] sdb1[1]
33553336 blocks super 1.2 [2/2] [UU]
unused devices: <none>
After nearly 12h, the resync was completed:
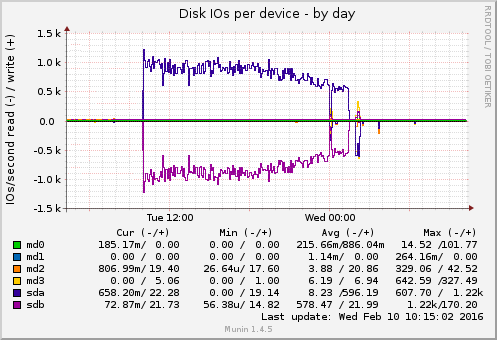
and then this happened:
# vzctl start 300
# vzctl enter 300
enter into CT 300 failed
Unable to open pty: No such file or directory
There are plenty of comments if you search for Unable to open pty: No such file or directory
But
# svzctl exec 300 /sbin/MAKEDEV tty
# vzctl exec 300 /sbin/MAKEDEV pty
# vzctl exec 300 mknod --mode=666 /dev/ptmx c 5 2
did not help:
# vzctl enter 300
enter into CT 300 failed
Unable to open pty: No such file or directory
And
# strace -ff vzctl enter 300
produces a lot of garbage – meaning stacktraces that did not help to solve the problem.
Then we were finally able to enter the container:
# vzctl exec 300 mount -t devpts none /dev/pts
But having a look into the process list was quite devastating:
# vzctl exec 300 ps -A
PID TTY TIME CMD
1 ? 00:00:00 init
2 ? 00:00:00 kthreadd/300
3 ? 00:00:00 khelper/300
632 ? 00:00:00 ps
That is not really what you expect when you have a look into the process list of a Mail-/Web-Server, isn’t it?
After looking araound into the system and searching through some configuration files, it became obvious, that there was a system update in the past, but someone forgot to install upstart. So that was easy, right?
# vzctl exec 300 apt-get install upstart
Reading package lists...
Building dependency tree...
Reading state information...
The following packages will be REMOVED:
sysvinit
The following NEW packages will be installed:
upstart
WARNING: The following essential packages will be removed.
This should NOT be done unless you know exactly what you are doing!
sysvinit
0 upgraded, 1 newly installed, 1 to remove and 0 not upgraded.
Need to get 486 kB of archives.
After this operation, 851 kB of additional disk space will be used.
You are about to do something potentially harmful.
To continue type in the phrase 'Yes, do as I say!'
?] Yes, do as I say!
BUT:
Err http://ftp.debian.org/debian/ wheezy/main upstart amd64 1.6.1-1
Could not resolve 'ftp.debian.org'
Failed to fetch http://ftp.debian.org/debian/pool/main/u/upstart/upstart_1.6.1-1_amd64.deb Could not resolve 'ftp.debian.org'
E: Unable to fetch some archives, maybe run apt-get update or try with --fix-missing?
No Network – doooh.
So… that was that. Another plan to: chroot. Let’s start:
First we need to shutdown the container – or at least what is running of it:
# vzctl stop 300
Stopping container ...
Container is unmounted
Second, we have to mount a bunch of devices to the FS:
# mount -o bind /dev /var/lib/vz/private/300/dev
# mount -o bind /dev/shm /var/lib/vz/private/300/dev/shm
# mount -o bind /proc /var/lib/vz/private/300/proc
# mount -o bind /sys /var/lib/vz/private/300/sys
Then perform the chroot and the installtion itself:
# chroot /var/lib/vz/private/300 /bin/bash -i
# apt-get install upstart
# exit
At last, umount all the things:
# umount -l /var/lib/vz/private/300/sys
# umount -l /var/lib/vz/private/300/proc
# umount -l /var/lib/vz/private/300/dev/shm
# umount -l /var/lib/vz/private/300/dev
If you have trouble, because some of the devices are busy, kill the processes you find out with:
# lsof /var/lib/vz/private/300/dev
Or just clean the whole thing
# lsof 2> /dev/null | egrep '/var/lib/vz/private/300'
Try to umount again :-).
Now restarting the container again.
# Starting container ...
# Container is mounted
# Adding IP address(es): 10.10.10.130
# Setting CPU units: 1000
# Setting CPUs: 2
# Container start in progress...
And finally:
# vzctl enter 300
root@300 #
root@300 # ps -A | wc -l
142
And this looks a lot better \o/.
Nice post. I learnt a few things. Always learning.
Thanks