Written by Philipp on 2007-12-05
kurzes Statement
Java . PersonalJetzt wo es an die Listen geht: ist so etwas REST konform? http://localhost/users?q=sonne Immerhin müsste ein Listenabruf ja per GET erfolgen, also kann man die query nicht per POST übermitteln. Was anderes am Rande: ich bin in der seltsamen Situation, einen Draytek Vigor 2930 VS hier zu haben und ihn nicht zu brauchen…. Was der
Written by Philipp on 2007-11-27
letzter Stand
Java . PersonalNachdem ich nun meine JRA jar habe und auch die restlet jar habe (Ich denke mir einfach mal, dass die vorausgesetzt wird). Habe ich mir nun eine einfache Klasse geschrieben (okay sie ist geklaut, aber ich will ja erstmal testen, wie was geht ^^): package de.hausswolff.cotodo.test; import java.util.List; import org.codehaus.jra.*; @HttpResource(location=”/customers”) public class Customers {
Written by Philipp on 2007-11-26
hands-on: Maven(2)
Build . Java . PersonalBevor ich dann endlich mal wieder etwas über meine eigentliche Arbeit poste, noch mal ein kleiner Abstecher zu dem Thema “Dinge die man nebenher sich aneignet”. Ich habe mich mal, nach dem Kommentar von Stefan bezüglich JRA umgesehen. Leider fand ich zuerst nur eine Source Version vom JRA Code, sodass ich mir erstmal die Fähigkeit
Written by Philipp on 2007-10-22
erster Eintrag erstellt!
Java . PersonalMittlerweile konnte ich jetzt auch schon den ersten Eintrag erstellen. Das ganze schaut noch recht umständlich aus, weil noch so gar keine Frontends existieren: public String addEntry(){ User recipient = (User)em.find(User.class, 3); Entry important = new Entry(); Calendar cal = Calendar.getInstance(); cal.set(2007, 12, 15); Date end = (Date) cal.getTime(); important.setSender(user); important.setRecipient(recipient); important.setPriority(1); important.setStatus(10); important.setTitle(“start with
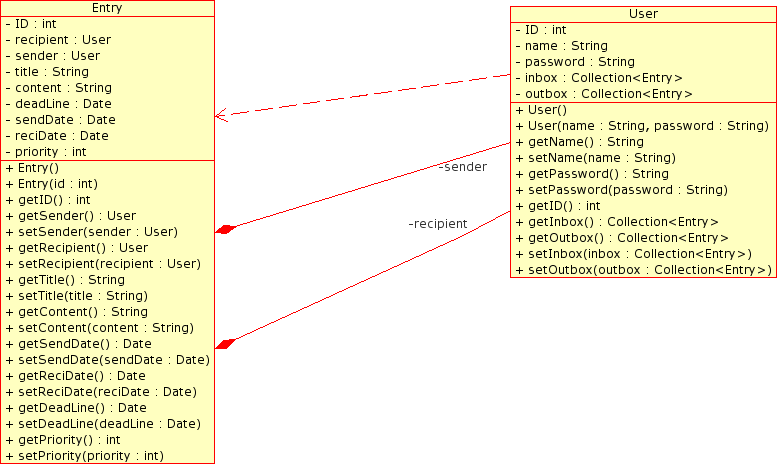
Written by Philipp on 2007-10-22
JPA YEEHA!
DB . Java . PersonalBesser später als nie, hier also dann mal – nach laaaanger Zeit mal wieder – mein aktueller Status. Mittlerweile bin ich ein ganzes Stück weiter und so fange ich sogar an, dem ganzen System von Persistence etwas abgewinnen zu können. Einzig die Frage bleibt, wieso JPA per default partout alle Feldnamen als groß schreibt. Naja
Written by Philipp on 2007-10-06
Was bisher so geschieht…
DB . Java . Personal . ToolingMoin… Ich wollte mal wieder ein wenig Feedback geben, woran ich bisher so sitze… Letztendlich bin ich endlich mit einer schönen Datenbankklasse ausgestattet, die mir auch die Dinge bietet, auf die ich angewiesen sein werde – ob da jetzt noch etwas dazu kommt, wird sich zeigen, aber erstmal reicht mir das, was bisher vorhanden ist.
Written by Philipp on 2007-09-09
simple iPhoto Gallery Script
Mac . Personal . PHPSome time ago, i searched for a very simple possibility for publishing some photos online. As a Mac User i am recently using iPhoto for collecting and organizing my photos. I reused some old PHP code and create a simple Script, that searches through some iPhoto Web Exports to build a nice index page with
Written by Philipp on 2007-09-04
FINALLY: Comments are working again
NAS . PHP . TechA friend of mine told me some minutes ago that the Comments function on this blog still produces some errors, when trying to post a comment. So i decided to stay with the spam and to disable the filter function until i have the time and the infos about the wordpress system to code my
Written by Philipp on 2007-08-31
mbff
Personal . PHP . TechVor einiger Zeit habe ich mit der Entwicklung eines Browser Games angefangen. Zu finden ist eine der ersten Versionen hier: http://mbff.hausswolff.de Da mir momentan die Zeit fehlt, es weiter zu entwickeln, und ich eh vorhatte den Server von PHP auf JSP umzustellen, habe ich alle alten Scripte gesammeln und stelle diese hier zum Download bereit.
Written by Philipp on 2007-08-28
Output an array as a bullet list.
PHP . SnippetsThis function parses an array recursive an creates a bullet list. Maybe is is usefull for somebody highlight_string(‘